Rookie2
||
Moin,
passiert in einem Resonator eigentlich mehr, als
nur bestimmte Frequenzen zu betonen und andere zu dämpfen?
Ist es möglich, durch bestimmte EQ-Einstellungen einen Klang
so klingen zu lassen, als sei er durch einen Gitarrenkorpus gespielt oder
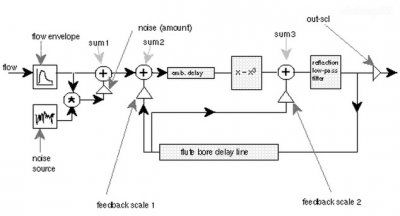
durch ein "Flötenrohr"?
Und wie kann man die Kennfrequenzen bestimmter Resonatoren herausbekommen?
Bei einer Gitarre müsste man doch eigentlich nur die Frequenzen eine direkt
aufgenommen Saite mit dem aufgenommenen Signal des schwingenden Gitarrenkorpus
vergleichen, um die Erhöhung/Dämpfung zu analysieren...?!
Gruß Rookie2
passiert in einem Resonator eigentlich mehr, als
nur bestimmte Frequenzen zu betonen und andere zu dämpfen?
Ist es möglich, durch bestimmte EQ-Einstellungen einen Klang
so klingen zu lassen, als sei er durch einen Gitarrenkorpus gespielt oder
durch ein "Flötenrohr"?
Und wie kann man die Kennfrequenzen bestimmter Resonatoren herausbekommen?
Bei einer Gitarre müsste man doch eigentlich nur die Frequenzen eine direkt
aufgenommen Saite mit dem aufgenommenen Signal des schwingenden Gitarrenkorpus
vergleichen, um die Erhöhung/Dämpfung zu analysieren...?!
Gruß Rookie2

 )
)