Auch gar nicht so einfach zu recherchieren, da das Tiefpassfilter von mp3 dynamisch mit der Bitrate variiert wird. Aber Frequenzen ober halb von 19kHz sind selbst bei 320kBit nur dann zu messen, wenn es beim Coding/Decoding Verzerrungen gibt (um diese zu vermeiden, soll man bei lautem Material ja ca. 1dB leister transcodieren).
Das ist deshalb nicht so leicht zu recherchieren, weil das ein Encoder „Feature“ ist, und nicht per se aus dem mp3 Standard kommt - und der Standard beschreibt ja nur den Decoder, nicht den Encoder.
Also ist das Tiefpass quasi ein Encoder Tuning Parameter. Die Encoder am Markt sind aber alle unterschiedlich getuned, und es gibt nach wie vor mehrere, unterschiedliche Encoder Implementierungen, mit unterschiedlichen Stärken und Schwächen.
Die Verhalten sich also alle leicht unterschiedlich, aber alle schreiben konforme und korrekte mp3 Dateien. Wenn man so will, klingen die eben ganz leicht unterschiedlich. Ob man das hören kann? Vermutlich nicht.
Anyway, zurück zum Tiefpassfilter. Generell ist das sinnvoll, weil
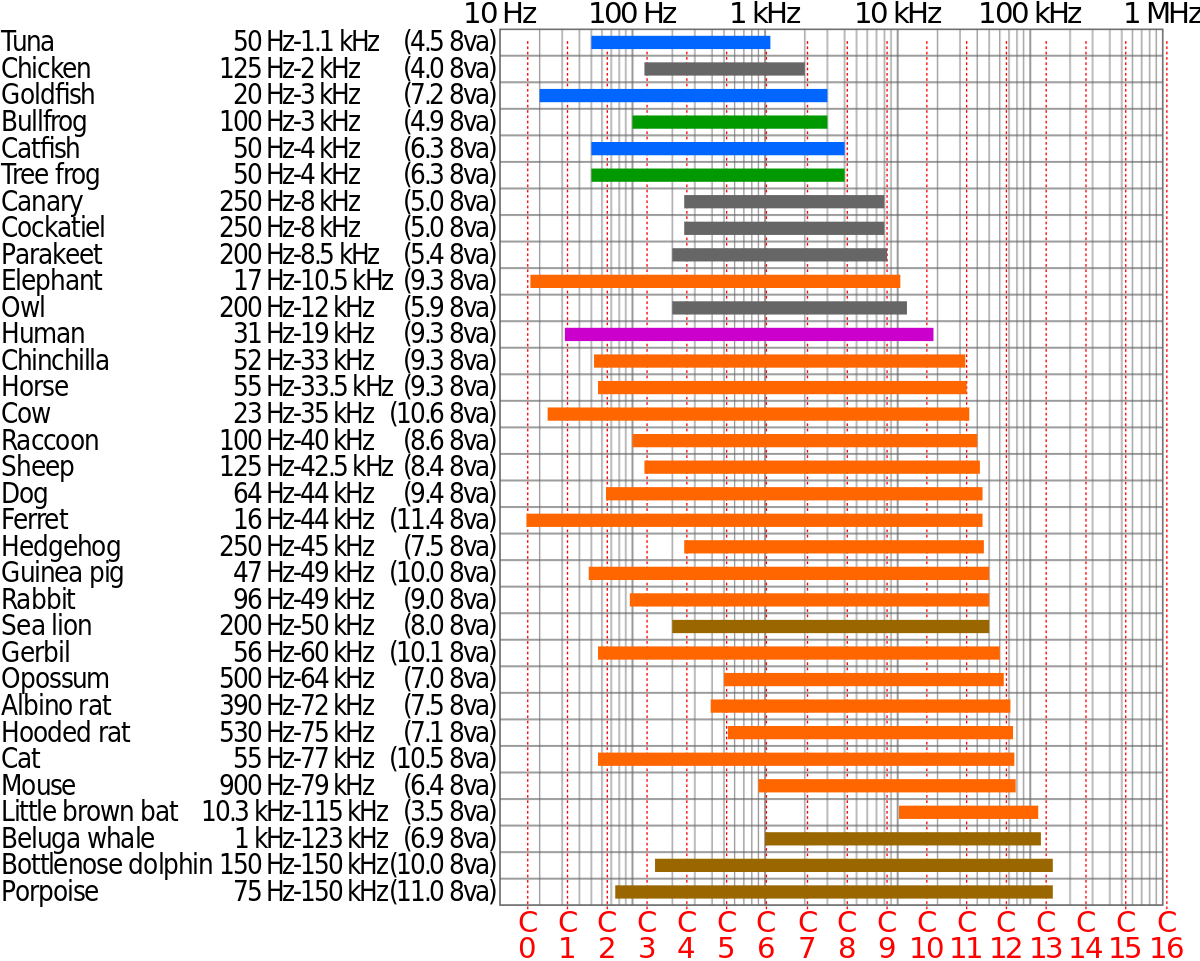
A) wie schon angemerkt die Messungen gleicher Lautheit und die Kurven der Hörschwelle in den oberen Frequenzen nicht existieren oder sehr ungenau sind - und nach diesen Messungen ist ja das psychoakustische Modell von mp3 entworfen worden. Wieviele Bits es für die Codierung dieser hohen Frequenzen benutzen soll ist also erst mal gar nicht so einfach zu bestimmen. Und bevor man zu viele spendiert, nimmt man lieber zu wenige, und spendiert lieber dort mehr, wo das Gehör generell empfindlicher ist.
B) streut ja der benefit dieser Frequenzen. Also was ich sagen will: viele Menschen hören bei 3khz sehr gut, bei 19khz sind’s aber nicht so viele. Viele Bits für diese Frequenzen zu spendieren, hilft also potenziell nur wenigen Leuten.
Soviel zur Motivation. Das genaue Tuning ist dann ein Freiheitsgrad für den Encoder Entwickler, von denen es, wie gesagt, so 3 oder 4 gibt.
MPEG-2 Layer 1 und 2, also was nach wie vor meist über DVB ins TV Gerät kommt, filtert übrigens bei afair 18khz. Unabhängig von der Bitrate.
Wie es bei AAC ist, weiß ich leider nicht.