4
4t6ßweuglerjhbrd
Guest
geändert 1.5.
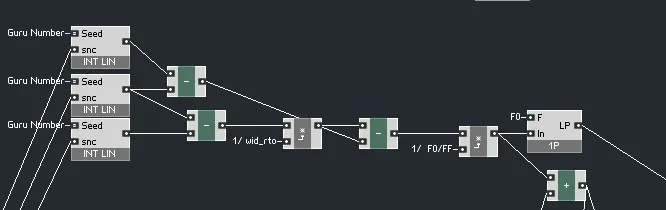
Worum es hier geht ist die Impulsformung zur Klangsynthese, die im Variophon verwendet wird.
Viele Informationen dazu finden sich auf der Seite http://www.variophon.de/index_d.htm
von Prof. Dr. Christoph Reuter.
Dazu schreibt er uns mit Link zu den Arbeiten und erwähnten Instrumenten (s.u.):
"Die formantbildenden Impulsfolgen für die Synthese von realistisch klingenden Blasinstrumentenklängen wurden 1975 von Jobst Fricke, Wolfgang Voigt und Jürgen Schmitz gefunden und wurde von Fricke 1975 auf der DAGA-Tagung zum ersten Mal vorgestellt (ebenso in der Dissertation von Wolfgang Voigt 1975).
Das Prinzip an sich findet sich schon bei Frans Fransson (1967), jedoch hat er damals noch nicht die Verbindung zwischen der Impulsformung und der Formantbildung bei verschiedenen Tonhöhen und Dynamikstufen gesehen.
1987 hatte Wolfgang Auhagen darauf aufbauend die Dreiecksimpulsfolgen für die Klangsynthese und eine Erklärung für die Anregungsfunktion bei Blasinstrumenten entdeckt/beschrieben und Johannes Blens 1993 war in seiner Staatsexamensarbeit der erste, der die Impulsformung mit beliebigen Formen auf eine digitale Ebene verlagerte.
Michael Oehler hatte dann im Rahmen seiner Dissertation (2008) mit Reaktor einige Variophonmodule als virtuelle Instrumente/Ensembles umgesetzt ( https://muwiserver.synology.me/oehler2008.zip ).
Während dieses Projekts entstanden auch einige gemeinsame Paper (auch über die Vorteile des Vibratos, wenn es direkt an der Anregungsfunktion ansetzt und nicht erst, wie z.B. beim Sampling, am fertigen Klang. Um 2012 gab es einige ganz spannende Versuche mit Studierenden hier in Wien das Variophon zu digitalisieren. Hier schrieben Ludwig Gredler-Ochsenbauer (2012) und Thassilo Gadermaier (2013) sehr feine Arbeiten über die Virtualiserung des Variophons als VST-Instrument (Gredler via SynthEdit) und als Matlab-Script (Gadermaier) und auch einige Studierendengruppen wagten sich an das Thema "gesampletes Variophon", wobei u.a. von Michael Alexander Brandstetter 2012 eine Kontakt-Library zum Variophon-Saxophon und zur Variophon-Oboe entstand (die Kontakt-Library und die VST-dll sind auch im Zip enthalten).
Michael Oehler und ich haben diese neueren Entwickungen 2014 in der Festschrift für Wolfgang Auhagen festgehalten."
Das zip File mit den Arbeiten und den Instrumenten findet sich hier:
--
Das Instrument und die Synthese finde ich sehr interessant, und wenn man sich praktisch damit beschäftigt fragt man sich
warum das nicht verbreiteter ist - ich bin erst durch @Area88 neulich drauf aufmerksam geworden.
Ich habe dabei festgestellt daß man damit auch andere Klänge sehr reizvoll synthetisieren kann und eine Methode
gefunden beliebige kurze Signale von Spektren mit der Wellenform der Impulsformung zu falten (Convolution)
als Alternatibe zu einer Filterbank, was eine ganze Palettte von anderen Klängen ermöglicht die im Klangverlauf sehr natürlich klingen und dabei sehr wenig Rechenkraft benötigen.
Beonders interessant finde ich auch daß die Impulsformung nur von nur zwei Parametern abhängt und idR ohne dyabamischen Filter auskommt und dabei eine recht komplexe aber natürlich Änderung des Spektrums (inklusive Lowpassfilterung) ermöglicht.
@serge hat weiter unten ausserdem auf den Mangrove Oszillator für Eurorack aufmerksam gemacht der ebenfalls die veränderliche
Dreieckspulswelle aus der Impulsformung nutzt und das mit Subharmonsischen wie im Trautonium (und FM) kombiniert,
was ich mir sehr interessant vorstelle.
Die nächsten, älteren Posts erklären die schnelle Faltung die ich anwende und die Erzuegung der Signale für die Spektren
mit Zufallsgeneratoren, was aber nur für bestimmte Klänge und Anwendungen Sinn macht, für andere sind klassichere
Signalwege sinnvoller, also Oszillator und nachgeschalteter Filter oder Filterbank.
__
Der Text hier wurde nachträglich eingefügt so daß sich einge Komemntare bis Post 45 auf älteres un teils geändertes beziehen.
Worum es hier geht ist die Impulsformung zur Klangsynthese, die im Variophon verwendet wird.
Viele Informationen dazu finden sich auf der Seite http://www.variophon.de/index_d.htm
von Prof. Dr. Christoph Reuter.
Dazu schreibt er uns mit Link zu den Arbeiten und erwähnten Instrumenten (s.u.):
"Die formantbildenden Impulsfolgen für die Synthese von realistisch klingenden Blasinstrumentenklängen wurden 1975 von Jobst Fricke, Wolfgang Voigt und Jürgen Schmitz gefunden und wurde von Fricke 1975 auf der DAGA-Tagung zum ersten Mal vorgestellt (ebenso in der Dissertation von Wolfgang Voigt 1975).
Das Prinzip an sich findet sich schon bei Frans Fransson (1967), jedoch hat er damals noch nicht die Verbindung zwischen der Impulsformung und der Formantbildung bei verschiedenen Tonhöhen und Dynamikstufen gesehen.
1987 hatte Wolfgang Auhagen darauf aufbauend die Dreiecksimpulsfolgen für die Klangsynthese und eine Erklärung für die Anregungsfunktion bei Blasinstrumenten entdeckt/beschrieben und Johannes Blens 1993 war in seiner Staatsexamensarbeit der erste, der die Impulsformung mit beliebigen Formen auf eine digitale Ebene verlagerte.
Michael Oehler hatte dann im Rahmen seiner Dissertation (2008) mit Reaktor einige Variophonmodule als virtuelle Instrumente/Ensembles umgesetzt ( https://muwiserver.synology.me/oehler2008.zip ).
Während dieses Projekts entstanden auch einige gemeinsame Paper (auch über die Vorteile des Vibratos, wenn es direkt an der Anregungsfunktion ansetzt und nicht erst, wie z.B. beim Sampling, am fertigen Klang. Um 2012 gab es einige ganz spannende Versuche mit Studierenden hier in Wien das Variophon zu digitalisieren. Hier schrieben Ludwig Gredler-Ochsenbauer (2012) und Thassilo Gadermaier (2013) sehr feine Arbeiten über die Virtualiserung des Variophons als VST-Instrument (Gredler via SynthEdit) und als Matlab-Script (Gadermaier) und auch einige Studierendengruppen wagten sich an das Thema "gesampletes Variophon", wobei u.a. von Michael Alexander Brandstetter 2012 eine Kontakt-Library zum Variophon-Saxophon und zur Variophon-Oboe entstand (die Kontakt-Library und die VST-dll sind auch im Zip enthalten).
Michael Oehler und ich haben diese neueren Entwickungen 2014 in der Festschrift für Wolfgang Auhagen festgehalten."
Das zip File mit den Arbeiten und den Instrumenten findet sich hier:
--
Das Instrument und die Synthese finde ich sehr interessant, und wenn man sich praktisch damit beschäftigt fragt man sich
warum das nicht verbreiteter ist - ich bin erst durch @Area88 neulich drauf aufmerksam geworden.
Ich habe dabei festgestellt daß man damit auch andere Klänge sehr reizvoll synthetisieren kann und eine Methode
gefunden beliebige kurze Signale von Spektren mit der Wellenform der Impulsformung zu falten (Convolution)
als Alternatibe zu einer Filterbank, was eine ganze Palettte von anderen Klängen ermöglicht die im Klangverlauf sehr natürlich klingen und dabei sehr wenig Rechenkraft benötigen.
Beonders interessant finde ich auch daß die Impulsformung nur von nur zwei Parametern abhängt und idR ohne dyabamischen Filter auskommt und dabei eine recht komplexe aber natürlich Änderung des Spektrums (inklusive Lowpassfilterung) ermöglicht.
@serge hat weiter unten ausserdem auf den Mangrove Oszillator für Eurorack aufmerksam gemacht der ebenfalls die veränderliche
Dreieckspulswelle aus der Impulsformung nutzt und das mit Subharmonsischen wie im Trautonium (und FM) kombiniert,
was ich mir sehr interessant vorstelle.
Die nächsten, älteren Posts erklären die schnelle Faltung die ich anwende und die Erzuegung der Signale für die Spektren
mit Zufallsgeneratoren, was aber nur für bestimmte Klänge und Anwendungen Sinn macht, für andere sind klassichere
Signalwege sinnvoller, also Oszillator und nachgeschalteter Filter oder Filterbank.
__
Der Text hier wurde nachträglich eingefügt so daß sich einge Komemntare bis Post 45 auf älteres un teils geändertes beziehen.
Zuletzt bearbeitet von einem Moderator: