24 Bit werden überschätzt.
Ich wiederhole mich mal (Murmeltiertag?): Warum schafft es RME nicht, THD+N auf der Aufnahmeseite auf einen niedrigeren Wert als 104dB zu drücken? Bei keinem einzigen selbst seiner neusten Geräte: nicht dem Fireface 802, nicht dem ADI-8 DS Mk III und nicht dem Fireface UFX. Kein Wandler unter 3000€ schafft mehr (und ob die noch teureren wirklich mehr schaffen, sei mal dahingestellt).
Wenn wir über 16 Bit vs. 24/32 Bit in Audiodateien reden, die analog aufgenommen wurden (also mit Mikro oder Tonabnehmer), dann enthalten Audiodateien mit 24 bis 32 Bit theoretisch allerhöchstens 4 Bit mehr Information als 16 Bit-Dateien.
Meistens jedoch ist das nicht der Fall, da es viele Fälle gibt, bei denen das Grundrauschen bereits vor der A/D-Wandlung zu laut ist:
1) Akustische Gitarre: Bei einem typischen Mikroabstand von 40 cm kommt das Signal bei durchschnittlichem Spiel vielleicht mit 80dB SPL an der Membran an. Das beste Studio-Kondensatormikrofon hat aber ein Eigenrauschen von 6dB SPL. Das heißt, die Gitarre liegt durchschnittlich bei bestem Equipment und allerbestem Aufnahmeraum (auf Federn gelagert, vollständig entkoppelte Raum-in-Raum-Konstruktion in einer Stadt ohne U-Bahn weit vom Bahnhof und jeder Straßenbahn entfernt, am besten tief in einem großen Wald) nur 74dB über dem unvermeidbaren Grundrauschen. Selbst mit 20dB Headroom (was bei akustischer Gitarre durchaus nicht übertrieben ist) reichen perfekte 16-Bit-Wandler (obwohl ich das natürlich nie machen würde).
Aber wenn ich die Gitarre mit 20dB Headroom und meinem Fireface aufgenommen habe, dann hebe ich die Lautstärke der Spur soweit an, daß ich nur noch ca. 1 bis 3dB Headroom habe und speichere das Ganze als 16-Bit-Audio-Datei und zwar völlig verlustfrei und meinetwegen auch ganz ohne Dithern, da die unteren 3.5 Bit sowieso nur noch das Mikrofonrauschen enthalten (und so lautes Grundrauschen muß man nicht mehr dithern).
2) Nachrichtensprecher: Bei 80dB SPL sind schon das höchste der Gefühle. Normale Sprache bekommt man verlustfrei in 16-Bit-Dateien.
3) Hörspielsprecher: Größere Variation der Lautstärke. Flüstern ist die Herausforderung schlechthin, da oft weniger als 60dB SPL erreicht werden, selbst wenn das Mikro 10 cm nahe an den Mundwinkel herangebracht werden kann. Bleiben 54dB Dynamik, da reicht schon fast eine 8-Bit-Audiodatei für eine verlustfreie Konservierung (aber wer würde da Platz sparen wollen?!).
Ganz wichtig ist aber, daß von uns allen fast niemand ein so toll schallbehandeltes Studio hat, daß er das Grundrauschen eines Mikrotech Gefell M940 hören könnte. Insofern sind die oben genannten 6dB SPL unvermeidbares Grundrauschen nur der theoretische Bestwert. Der reale wird allein schon dadurch verschlechtert, daß der Gitarrenspieler/Sprecher nicht nur atmet, sondern sich auch bewegt. Rascheln der Kleidung kann unglaublich laut sein wenn man als Toning drauf achtet.
Wir hatten mal eine Profisprecherin da, alles lief perfekt, aber in den späteren Aufnahmen sah und hörte man ganz leise in regelmäßigen Abständen Klicks. Kaputte Wandler? Neonröhre? Am Ende wars das Ticken einer leisen Frauenarmbanduhr, die sie bei den Aufnahmen am Handgelenk in ihrem Schoß 1m vom Mikro entfernt getragen hatte.
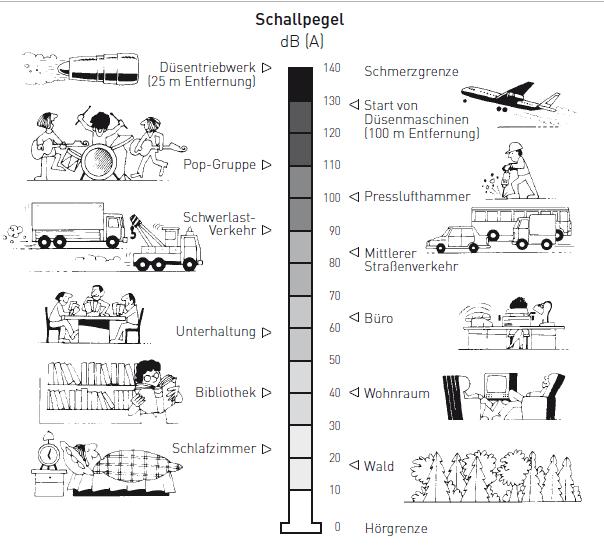
Take-Home-Message: Es gibt wenige bis keine realen Audio-Ereignisse, von denen man mehr als 16 Bit bekommt (dazu müssen sie nämlich immer lauter als 6 + 96 dB SPL sein. Und nun gucken wir mal in das schöne Bild von swissdoc:
Demnach wäre ein Presslufthammer fast schon zu leise. Fairerweise muß man sagen, daß hier eine riesige Menge akustischer Instrumente fehlt, die locker 110 dB SPL überschreiten können (Drums, Trompete, Shouts, ...)
Und zum Schluß eine Lanze für 24-Bit-Dateien: Ich muß nicht normalisieren und kann dadurch die originalen Lautstärkeverhältnisse bewahren, wenn ich alles mit der gleichen Preamp-Einstellung und Mikroposition aufnehme.