Bei Granular-Hardware bin ich persönlich ein Fan vom bereits erwähnten (BeetleCrab) Tempera. Das Ding ist von den Parametern her im Vergleich zum Wettbewerb vielleicht etwas eingeschränkt, aber ich finde es in der Anwendung sehr musikalisch. ... macht einfach Spaß, ... sieht dabei noch schön aus, ... und was das Klangpotential angeht, kratze ich immer noch an der Oberfläche (... kann irgendwie wörtlich genommen werden :D). MPE habe beispielsweise noch nicht ausprobiert ... muss ich die Tage mal machen (Mein Osmose ist aus der Reparatur zurück

... hatte ihn vom Keyboardständer geworfen.

).
Die Bedienung des Tempera ist übrigens weniger kryptisch, als es auf den ersten Blick den Anschein hat.
Tipp: ... mal genauer anschauen!
")
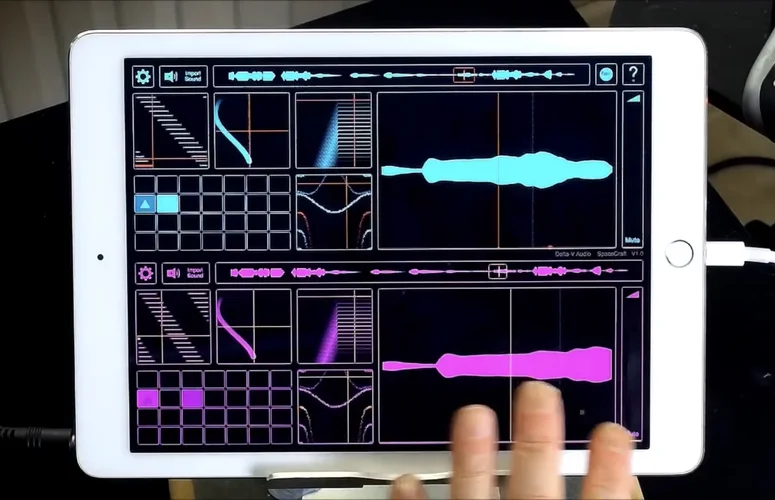

 ... daher dieser Beitrag
... daher dieser Beitrag  .
.