A
Anonymous
Guest
sägezahn-smoo schrieb:Ich zitiere nur John Bowen. Er wollte das feature eine Weile unbedingt haben und musste es nun verschieben, da digital nicht so einfach.
John: "But with all the digital voices being summed prior to a final stereo buss, there seems to be some issues."
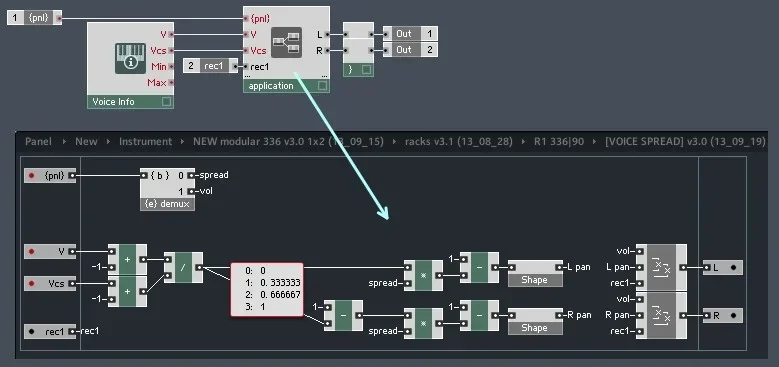
Da liegt das Missverständnis: sein Problem ist ein anderes, nicht daß es digital per se schwer wäre,
sondern die Voicearchitektur die er gewählt hat, offensichtlich gibt es nur
eine Monosumme vor den Effekten (die dann wohl ebenfalls nur Monoinput haben).
Etwas grob ausgedrückt also kein Digitalproblem, sondern ein Bowen-Problem.
Ich glaub es wär interessant die Gegenfrage zur ursprünglichen zu stellen:
welche VAs haben denn kein Panning pro Voice?
- Solaris
- ... ?