G
GegenKlang
Fehlermacher
Hallo,
klassisches weißes Rauschen wird ja einfach mit gleichverteilten Zufallswerten generiert. Rosa rauschen, braunes oder rotes Rauschen entsteht, indem man weißes Rauschen durch Low-Pass-Filter jagt, soweit habe ich es zumindest verstanden. Richtig?
Inspiriert von der Voss-Methode zur Generierung von fraktalem Rauschen (n. Gareth: Musimathics I), die von einer Grundfrequenz f ausgehend nur alle n Samples – n = SAMPLING_RATE / f – die Amplitude auf einen anderen Zufallswert ändert und auf diesem Prinzip basierend auch Werte für 2f, 4f, 8f, ... 2^x*f würfelt und reinmittelt.
Das hat mich doch sehr daran erinnert, wie harmonische Klänge entstehen: Teiltöne mit verschiedenen Amplitudenmaxima und Hüllkurven, deren Frequenzen jeweils ein vielfaches der Grundfrequenz ... und so weiter, euch brauch ich das bestimmt nicht wiederkäuen.
Jedenfalls könnte man doch diese Teilräusche analog zusammensetzen, also einfach mit Vielfachen statt Zweierpotenzen arbeiten, und jedem Teilrausch eine eigene Hüllkurve verpassen, oder?
Meine Frage: Wie immer eine nette Vorstellung, aber auch etwas unrealistisch, dass meine Idee was bahnbrechend neues wäre, zumal sie ja ziemlich trivial ist. Kennt man dieses Verfahren unter einem Namen? Geht mir ständig so, dass ich ein Rad neu erfinde und dann nicht zu bezeichnen weiß. Den Oszillator, der einfach f-mal die Sekunde die Amplitude auf einen anderen Zufallswert ändert, hab ich einfach mal provisorisch "crack" getauft in meinem Soft-Synthi-Projekt, und eingereiht zu den anderen Oszi-Primitiven "sine", "square", "sawtooth", "triangle" und "noise".
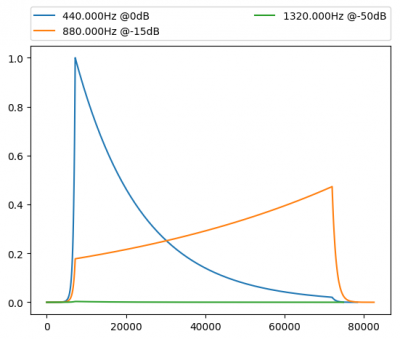
Anhang 1: Teilräusche und ihre Amplitudenverläufe, fürs Auge
Anhang 2: Dasselbe für Ohren
Anhang 3: Zum Vergleich, die Variante mit äh, selbes Problem ... "frequency-based constrained noise" (vermutlich = Braunes Rauschen)
Viele Grüße,
flowdy
P.S. Mein Soft-Synthi-Projekt habe ich schon mal an anderer Stelle in diesem Forum vorgestellt. Leider bisher keine Resonanz, womöglich war das Unterforum auch haarscharf an der Zielgruppe vorbei? Verschiebungsaktionen stehe ich offen gegenüber.
klassisches weißes Rauschen wird ja einfach mit gleichverteilten Zufallswerten generiert. Rosa rauschen, braunes oder rotes Rauschen entsteht, indem man weißes Rauschen durch Low-Pass-Filter jagt, soweit habe ich es zumindest verstanden. Richtig?
Inspiriert von der Voss-Methode zur Generierung von fraktalem Rauschen (n. Gareth: Musimathics I), die von einer Grundfrequenz f ausgehend nur alle n Samples – n = SAMPLING_RATE / f – die Amplitude auf einen anderen Zufallswert ändert und auf diesem Prinzip basierend auch Werte für 2f, 4f, 8f, ... 2^x*f würfelt und reinmittelt.
Das hat mich doch sehr daran erinnert, wie harmonische Klänge entstehen: Teiltöne mit verschiedenen Amplitudenmaxima und Hüllkurven, deren Frequenzen jeweils ein vielfaches der Grundfrequenz ... und so weiter, euch brauch ich das bestimmt nicht wiederkäuen.
Jedenfalls könnte man doch diese Teilräusche analog zusammensetzen, also einfach mit Vielfachen statt Zweierpotenzen arbeiten, und jedem Teilrausch eine eigene Hüllkurve verpassen, oder?
Meine Frage: Wie immer eine nette Vorstellung, aber auch etwas unrealistisch, dass meine Idee was bahnbrechend neues wäre, zumal sie ja ziemlich trivial ist. Kennt man dieses Verfahren unter einem Namen? Geht mir ständig so, dass ich ein Rad neu erfinde und dann nicht zu bezeichnen weiß. Den Oszillator, der einfach f-mal die Sekunde die Amplitude auf einen anderen Zufallswert ändert, hab ich einfach mal provisorisch "crack" getauft in meinem Soft-Synthi-Projekt, und eingereiht zu den anderen Oszi-Primitiven "sine", "square", "sawtooth", "triangle" und "noise".
Anhang 1: Teilräusche und ihre Amplitudenverläufe, fürs Auge
Anhang 2: Dasselbe für Ohren
Anhang 3: Zum Vergleich, die Variante mit äh, selbes Problem ... "frequency-based constrained noise" (vermutlich = Braunes Rauschen)
Viele Grüße,
flowdy
P.S. Mein Soft-Synthi-Projekt habe ich schon mal an anderer Stelle in diesem Forum vorgestellt. Leider bisher keine Resonanz, womöglich war das Unterforum auch haarscharf an der Zielgruppe vorbei? Verschiebungsaktionen stehe ich offen gegenüber.